Run in Postman
- Requisitos de arquivo
- Propriedades necessárias para importações de registros e atividades
- Propriedades necessárias para importações de participantes de eventos de marketing
Iniciar uma importação
É possível iniciar uma importação fazendo umaPOST solicitar /crm/v3/imports com um corpo de solicitação que especifica como mapear as colunas do seu arquivo de importação para as propriedades associadas no HubSpot.
As importações de API são enviadas como solicitações de tipo de dados de formulário, com o corpo de solicitação contendo os seguintes campos:
- importRequest: um campo de texto que contém o JSON da solicitação.
- arquivos: um campo de arquivo que contém o arquivo de importação.
Content-Type com um valor de multipart/form-data.
A captura de tela a seguir mostra como a solicitação pode parecer ao usar um aplicativo como o Postman:
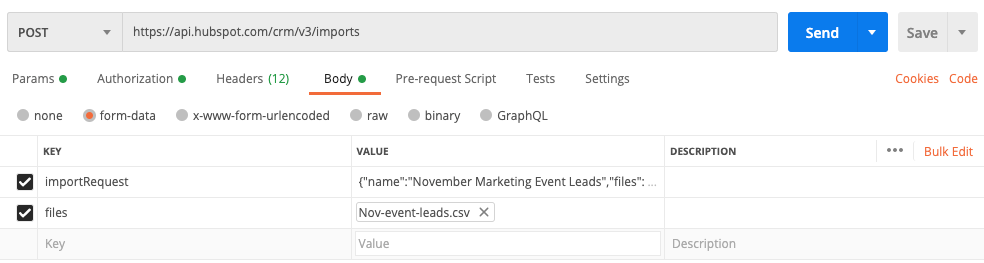
Formatar dados de importRequest
Em sua solicitação, defina os detalhes do arquivo de importação, incluindo o mapeamento das colunas da planilha para os dados do HubSpot. Sua solicitação deve incluir os seguintes campos:- nome: o nome da importação. No HubSpot, esse é o nome exibido na ferramenta de importação, bem como o nome que você pode usar em outras ferramentas, como listas.
- importOperations: um campo opcional usado para indicar se a importação deve apenas criar e atualizar, apenas criar ou apenas atualizar registros para um determinado objeto ou atividade. Inclua o
objectTypeIdpara o objeto/atividade e, se você quiserUPSERT(criar e atualizar),CREATEouUPDATEregistros. Por exemplo, o campo ficaria assim na solicitação:"importOperations": {"0-1": "CREATE"}. Se você não incluir este campo, o valor padrão usado para a importação seráUPSERT. - dateFormat: o formato para datas incluídas no arquivo. Por padrão, isso é definido como
MONTH_DAY_YEAR, mas você também pode usarDAY_MONTH_YEARouYEAR_MONTH_DAY. - marketableContactImport: o status de marketing dos contatos no arquivo de importação. Isso é usado apenas ao importar contatos para contas com acesso aos contatos de marketing. Para definir os contatos no arquivo como autorizados para marketing, use o valor
true. Para definir os contatos no arquivo como não autorizados para marketing, use o valorfalse. - createContactListFromImport: um campo opcional para criar uma lista estática dos contatos da sua importação. Para criar uma lista a partir do seu arquivo, use o valor
true. - arquivos: uma matriz que contém as informações do arquivo de importação.
- fileName: o nome do arquivo de importação.
- fileFormat: o formato do arquivo de importação. Para arquivos CSV, use o valor
CSV. Para planilhas do Excel, use o valorSPREADSHEET. - fileImportPage: contém a matriz
columnMappingsnecessária para mapear os dados do seu arquivo de importação para os dados do HubSpot. Saiba mais sobre o mapeamento de colunas abaixo.
Mapear colunas de arquivo para propriedades do HubSpot
Dentro da matrizcolumnMappings, inclua uma entrada para cada coluna no seu arquivo de importação, correspondendo à ordem do cabeçalho da coluna da sua planilha.
Para cada coluna, inclua os seguintes campos:
- columnObjectTypeId: o nome ou valor
objectTypeIddo objeto ou atividade ao qual os dados pertencem. Consulte este artigo para obter uma lista completa de valoresobjectTypeId. - columnName: o nome do cabeçalho da coluna. Isso deve corresponder exatamente ao nome do cabeçalho da coluna no arquivo.
- propertyName: o nome interno da propriedade do HubSpot para a qual os dados serão mapeados. Para a coluna comum em importações de vários arquivos,
propertyNamedeve sernullquandotoColumnObjectTypeIdé usado. - columnType: usado para especificar que uma coluna contém um propriedade de identificador exclusivo. Dependendo da propriedade e do meta da importação, use um dos seguintes valores:
- HUBSPOT_OBJECT_ID: o ID de um registro. Por exemplo, o arquivo de importação de contatos pode conter uma coluna de ID do registro, que armazena o ID da empresa à qual você deseja associar os contatos.
- HUBSPOT_ALTERNATE_ID: um identificador exclusivo que não seja o ID do registro. Por exemplo, o arquivo de importação de contatos pode conter uma coluna de E-mail, que armazena os endereços de e-mail dos contatos.
- FLEXIBLE_ASSOCIATION_LABEL: inclua este tipo de coluna para indicar que a coluna contém rótulos de associação.
- ASSOCIATION_KEYS: apenas para as importações de uma mesma associação de objeto, inclua este tipo de coluna para o identificador exclusivo dos mesmos registros de objeto que você está associando. Por exemplo, em sua solicitação para uma importação de associação de contatos, a coluna Contato Associado \[ID de e-mail/Registro] deve ter um
columnTypedeASSOCIATION_KEYS. Saiba mais sobre como configurar o seu arquivo de importação para uma importação de mesma associação de objeto.
- toColumnObjectTypeId: para importações de vários arquivos ou de vários objetos, o nome ou
objectTypeIddo objeto a que pertence a propriedade de coluna comum ou o rótulo de associação. Inclua esse campo para a propriedade de coluna comum no arquivo do objeto ao qual a propriedade não pertence. Por exemplo, se estiver associando contatos e empresas em dois arquivos com o E-mail da propriedade do contato como a coluna comum, incluatoColumnObjectTypeIdpara a coluna E-mail no arquivo da empresa. - foreignKeyType: apenas para importações de vários arquivos, o tipo de associação que a coluna comum deve usar, especificada pelo
associationTypeIdeassociationCategory. Inclua esse campo para a propriedade de coluna comum no arquivo do objeto ao qual a propriedade não pertence. Por exemplo, se estiver associando contatos e empresas em dois arquivos com o E-mail da propriedade do contato como a coluna comum, incluaforeignKeyTypepara a coluna E-mail no arquivo da empresa. - associationIdentifierColumn: apenas para importações de vários arquivos, indica a propriedade usada na coluna comum para associar os registros. Inclua esse campo para a propriedade de coluna comum no arquivo do objeto ao qual a propriedade pertence. Por exemplo, se estiver associando contatos e empresas em dois arquivos com o E-mail da propriedade do contato como a coluna comum, defina
associationIdentifierColumncomotruepara a coluna de E-mail no arquivo do contato.
Importar um arquivo com um objeto
Veja abaixo um exemplo do corpo de solicitação de importação de um arquivo para criar contatos:- JSON
Importar um arquivo com vários objetos
Veja abaixo um exemplo de solicitação de importação e associação de contatos e empresas em um único arquivo com rótulos de associação:- JSON
Importar vários arquivos
Veja abaixo um exemplo de corpo de solicitação de importação e associação de contatos e empresas em dois arquivos, onde o E-mail da propriedade do contato é a coluna comum nos arquivos:- JSON
importId, que poderá ser usado para recuperar ou cancelar a importação. Uma vez concluída, você poderá exibir a importação no HubSpot, mas as importações concluídas por meio da API não estarão disponíveis como uma opção ao filtrar registros por importação em exibições, listas, relatórios ou fluxos de trabalho.
Obter importações anteriores
Para recuperar todas as importações da sua conta da HubSpot, faça uma solicitaçãoGET para /crm/v3/imports/. Para recuperar informações para uma importação específica, faça uma solicitação GET para /crm/v3/imports/{importId}.
Ao recuperar importações, as informações serão retornadas, incluindo o nome, a fonte, o formato de arquivo, o idioma, o formato de data e os mapeamentos de coluna da importação. O state da importação também será retornado, que pode ser qualquer um dos seguintes:
STARTED: o HubSpot reconhece que a importação existe, mas a importação ainda não começou a ser processada.PROCESSING: a importação está sendo processada ativamente.DONE: a importação foi concluída. Todos os objetos, atividades ou associações foram atualizados ou criados.FAILED: ocorreu um erro que não foi detectado quando a importação foi iniciada. A importação não foi concluída.CANCELED: o usuário cancelou a exportação enquanto estava em qualquer um dos estadosSTARTED,PROCESSINGouDEFERRED.DEFERRED: o número máximo de importações (três) estão sendo processadas ao mesmo tempo. A importação começará assim que uma das outras importações terminar o processamento.
Cancelar uma importação
Para cancelar uma importação ativa, faça uma solicitaçãoPOST para /crm/v3/imports/{importId}/cancel.
Exibir e solucionar erros de importação
Para exibir erros de uma importação específica, faça uma solicitaçãoGET para /crm/v3/imports/{importId}/errors. Saiba mais sobre erros comuns de importação e como resolvê-los.
Para erros como Número incorreto de colunas, Não é possível analisar o JSON ou 404 texto/html não é aceito:
- Verifique se há um cabeçalho para cada coluna no arquivo e se o corpo da solicitação contém um
columnMappingpara cada coluna. Os seguintes critérios devem ser atendidos:- A ordem das colunas no corpo da solicitação e no arquivo de importação devem coincidir. Se a ordem das colunas não coincidir, o sistema tentará reclassificá-las automaticamente, mas poderá não ser bem-sucedido, resultando em um erro quando a importação for iniciada.
- Cada coluna precisa ser mapeada. Se uma coluna não for mapeada, a solicitação de importação ainda poderá ser bem-sucedida, mas resultará no erro Número incorreto de colunas quando a importação for iniciada.
- Verifique se o nome do arquivo e o campo
fileNamena sua solicitação JSON coincidem e se você incluiu a extensão de arquivo no campofileName. Por exemplo, import_name.csv. - Verifique se o cabeçalho inclui
Content-Typecom um valor demultipart/form-data.